Cluster file organization is different from the other file organization methods. Other file organization methods mainly focus on organizing the records in a single file (table). Cluster file organization is used, when we frequently need combined data from multiple tables.
While other file organization methods organize tables separately and combine the result based on the query, cluster file organization stores the combined data of two or more frequently joined tables in the same file known as cluster. This helps in accessing the data faster.
Types of Cluster File Organization
There are two types of cluster file organizations:
- Index based cluster file organization
- Hash based cluster file organization
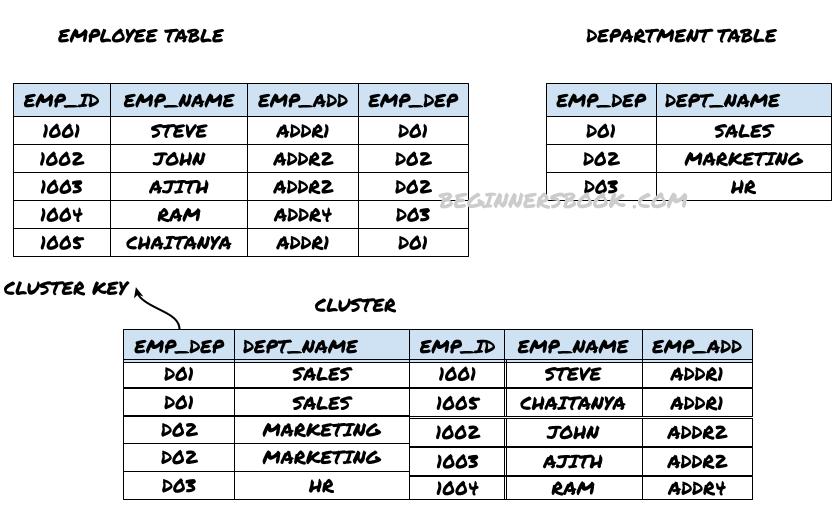
Index based cluster file organization: The example that we have shown in the above diagram is an index based cluster file organization. In this type, the cluster is formed based on the cluster key and this cluster key works as an index of the cluster.
Since EMP_DEP field is common in both the tables, this becomes the cluster key when these two tables joined to form the cluster. Whenever we need to find the combined record of employees and department based on the EMP_DEP, this cluster can be used to quickly retrieve the data.
Hash based cluster file organization: This is same as index based cluster file organization except that in this type, the hash function is applied on the cluster key to generate the hash value and that value is used in the cluster instead of the index.
Note: The main difference between these two types is that in index based cluster, records are stored with cluster key while in hash based cluster, the records are stored with the hash value of the cluster key.
Advantages of cluster file organization
- This method is popularly used when multiple tables needs to be joined frequently based on the same condition.
- When a table in database is joined with multiple tables of the same database then cluster file organization method will be more efficient compared to other file organization methods.
Disadvantages of cluster file organization
- Not suitable for large databases: This method is not suitable if the size of the database is huge as the performance of various operations on the data will be poor.
- Not flexible with joining condition: This method is not suitable if the join condition of the tables keep changing, as it may take additional time to traverse the joined tables again for the new condition.
- Isolated tables: If tables are not that related and there is rarely any join query on tables then using this file organization is not recommended. This is because maintaining the cluster for such tables will be useless when it is not used frequently.
Leave a Reply