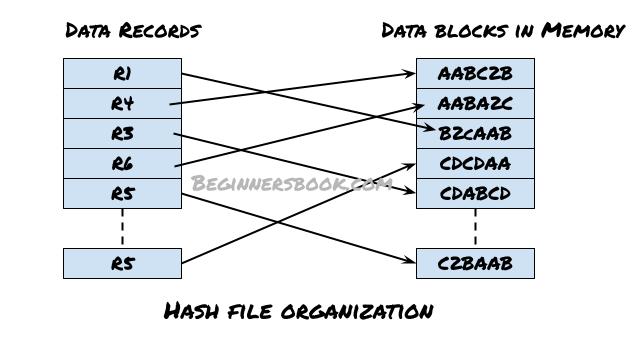
In this method, hash function is used to compute the address of a data block in memory to store the record. The hash function is applied on certain columns of the records, known as hash columns to compute the block address. These columns/fields can either be key or non-key attributes.
The following diagram demonstrates, the hash file organization. As shown here, the records are stored in database in no particular order and the data blocks are not consecutive. These memory addresses are computed by applying hash function on certain attributes of these records.
Fetching a record is faster in this method as the record can be accessed using hash key column. No need to search through the entire file to fetch a record.
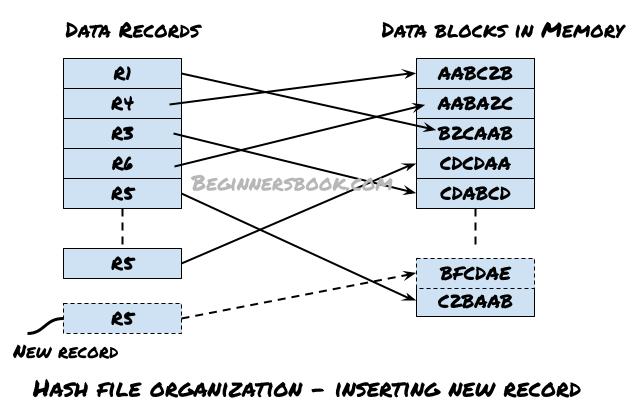
Inserting a record using Hash file Organization method
In the following diagram, you can see that a new record R5 needs to be added to the file. The same hash function that generated the address for existing records in the file, will be used again to compute the address (find data block in memory) for this new record by applying the has function on the certain columns of this record.
Advantages of Hash File Organization
- This method doesn’t require sorting explicitly as the records are automatically sorted in the memory based on hash keys.
- Reading and fetching a record is faster compared to other methods as the hash key is used to quickly read and retrieve the data from database.
- Records are not dependant on each other and are not stored in consecutive memory locations so that prevents the database from read, write, update, delete anomalies.
Disadvantages of Hash File Organization
- Can cause accidental deletion of data, if columns are not selected properly for hash function. For example, while deleting an Employee
"Steve"usingEmployee_Nameas hash column can cause accidental deletion of other employee records if the other employee name is also"Steve". This can be avoided by selecting the attributes properly, for example in this case combining age, department or SSN with the employee_name for hash key can be more accurate in finding the distinct record. - Memory is not efficiently used in hash file organization as records are not stored in consecutive memory locations.
- If there are more than one hash columns, searching a record using a single attribute will not give accurate results.
Leave a Reply