Heap File Organization method is simple yet powerful file organization method. In this method, the records are added in memory data blocks, in no particular order.
The following diagram demonstrates the Heap file organization. As you can see, records have been assigned to data blocks in memory in no particular order.
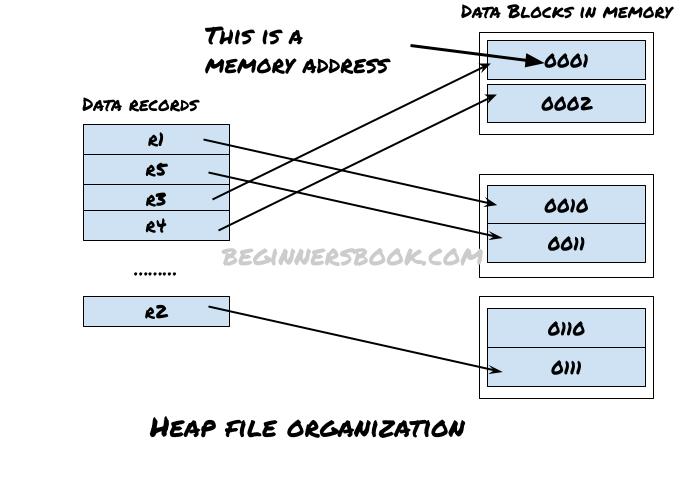
Since the records are not sorted and not stored in consecutive data blocks in memory, searching a record is time consuming process in this method. Update and delete operations also give poor performance as the records needs to be searched first for updation and deletion, which is already a time consuming operation. However if the file size is small, these operations give one of the best performances compared to other methods so this method is widely used for small size files.
This method requires memory optimization and cleanup as this method doesn’t free up the allocated data block after a record is deleted.
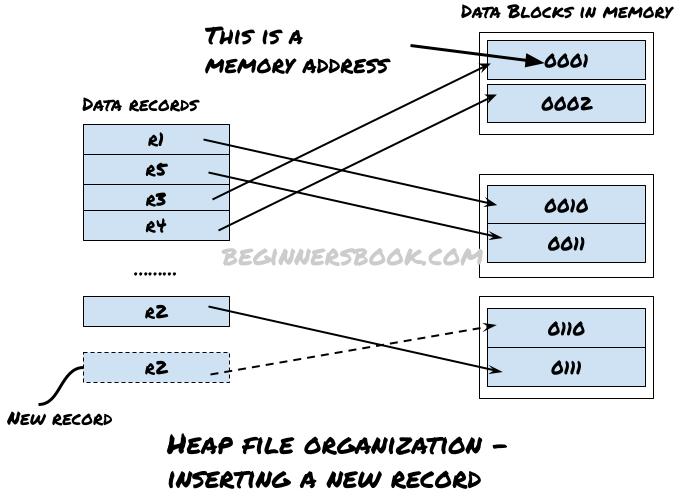
Insertion of a record using Heap File Organization method
The following diagram demonstrate the addition of a new record in the file using heap file organization method. As you can see a free data block which has not been assigned to any record previously, has been assigned to the newly added record R2. The insertion of new record is pretty simple in this method as there is no need to perform any sorting, any free data block is assigned to the new record.
Advantages of Heap File Organization Method
- This is a popular method when huge amount of records needs to be added in the database. Since the records are assigned to free data blocks in memory there is no need to perform any special check for existing records, when a new record needs addition. This makes it easier to insert multiple records all at once without worrying about messing with the file organization.
- When the records are less and file size is small, it is faster to search and retrieve the data from database using heap file organization compared to sequential file organization.
Disadvantages of Heap File Organization method
- This method is inefficient if the file size is big, as the search, retrieve and update operations consumes more time compared to sequential file organization.
- This method doesn’t use the memory space efficiently, thus it requires memory cleanup and optimization to free the unused data blocks in memory.
Leave a Reply