In the previous chapter, you learned how to recover a transaction using log based recovery method in DBMS. In this guide, you will learn how to use checkpoint in database and how to recover a failed transaction using checkpoint.
What is a checkpoint?
- Checkpoint is like a bookmark in the transaction that helps us rollback a transaction till a certain point.
- These are really useful when a transaction performs several operations. If such transaction fail at any point of time, instead of undoing the whole transaction, we can rollback to a certain checkpoint.
- We can have more than one checkpoint in a transaction. These checkpoints can be given any name so it’s easier to identify the particular point in the transaction and rollback to a certain point in case of failure.
- You can say that by using checkpoints, you can divide the transaction in smaller parts. Once a checkpoint is reached, the changes are made permanent in the database till that point and the log entries are removed. This is because that part of the transaction is successfully completed so there is no need to roll back or redone, thus no need to maintain those logs.
- A checkpoint represents a point till which all transactions are completed and database is in consistent state.
Recovery using Checkpoint
Let’s understand how to recover a failed transaction using checkpoint.
- The recovery system reads the log file in reverse (from end to start).
- Recovery system maintains two files: one is redo-list file and second is undo-list file. One or both of these files are used to recover a failed transaction.
- If the recovery system finds a log entry with
<Tn, Start>and<Tn, Commit>or just<Tn, Commit>, it puts the transaction in the redo-list. This is because a commit statement represents that some of transactions in this schedule are made permanent using commit statement, so it becomes important to redone the failed transactions. - If the recovery system finds a log entry with
<Tn, Start>but no entry with<Tn, commit>or<Tn, Abort>, it puts the transaction in undo-list. This is because no transaction made the changes permanent in the database as no commit statements found, in this case the transaction can be rolled back by putting it in undo-list.
Example:
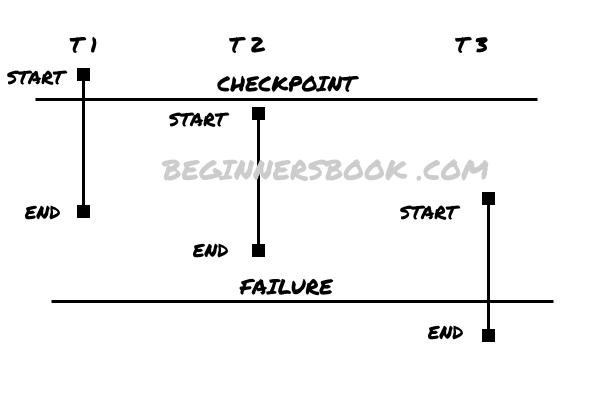
In the following diagram you can see a schedule with three transactions T1, T2 and T3. Since the log entries are removed once a checkpoint is found, the entry <T1, Start> is not in the log as it is before the checkpoint and the log is cleared at checkpoint. The entries that are there in the log are <T1, Commit>, <T2, Start>, <T2, Commit> and <T3, Start>. The entry <T3, Commit> is not in the log because the transaction is failed before that.
So based on the rules that we have seen above, T1 and T2 are put in redo-list as <T1, Commit> and <T2, Commit> present in log file. Transaction T3 is put in undo-list as <T3, Start> is found but no entry for <T3, Commit> or <T3, Abort>.
Checkpoint Implementation Considerations
- Frequency: Checkpoint should be implemented frequently enough to ensure that the recovery is smooth but you should be careful while doing this, if done so frequently then it can cause significant performance overhead.
- System Load: Checkpoint should be implemented in such a way that they occur during when system load is not high. This can minimize performance impact.
Leave a Reply