Data replication is a process of making the multiple copies of database available on servers. This is done to achieve distributed database. This is to minimize the load on the database and provide better performance to the users.
- In Data replication, the various users can access data from different sites available on distributed system, however the data remains same in all sites. Replication is done in such a way so that the data is always same on all sites and synchronized whenever there is a change.
- This distributed database approach provides better performance and availability. It also helps to recover data in case of a server failure.
- There can be full replication where the entire database is available on all servers or there can be partial replication where the frequently used chunks of data are available on all servers.
- The transactional replication works on a concept of publisher and subscriber.
Publisher: The primary database that publishes data to all the secondary databases called subscribers.
Subscriber: These are the secondary databases, these are nothing but the copies of the primary database. These subscriber receives updates from the publisher as and when there is a change in the publisher database.
Types of Data Replication
There are three types of data replication approaches in DBMS:
1. Transactional replication
2. Snapshot replication
3. Merge replication
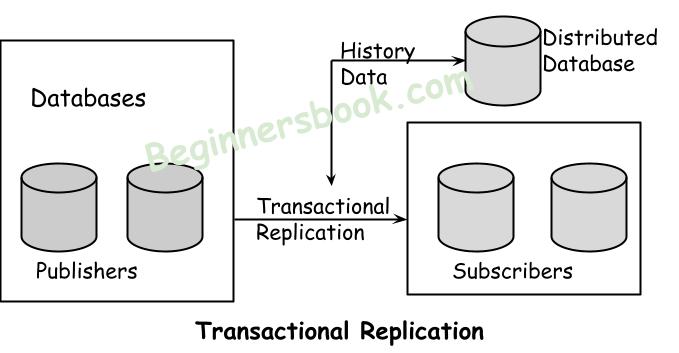
1. Transactional replication
This approach is used to replicate the changes between multiple copies of databases. Any change such as data update, primary key change, stored procedure change is replicated among all copies of the database.
The changes occur in the subscriber in the same order in which they occurred in the publisher database.
Subscriber databases can be used as read-only databases. The consistency between publisher and subscriber is guaranteed as the publisher push all the changes to subscribers consistently and in same order.
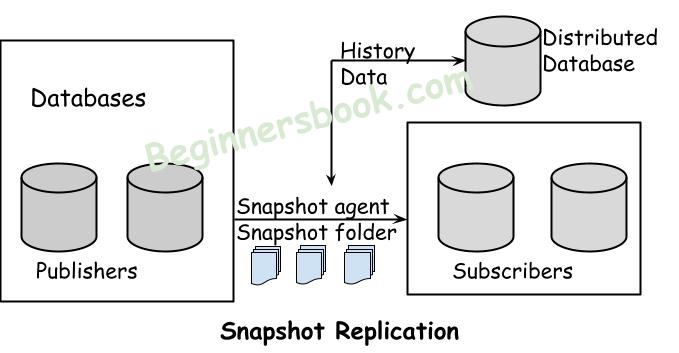
2. Snapshot replication
In this approach, the snapshot of publisher database is taken at a specific moment of time and that snapshot is shared with all the subscribers.
Snapshot replication is slower than transactional replication, as the changes are not pushed real-time rather they are pushed after a specific interval.
This approach is mostly used when:
- Data does not change frequently.
- Initial replication of data between Publisher and Subscriber.
- A big change is happened in the publisher database (source database).
Role of snapshot agent in Snapshot replication: Snapshot agent is responsible for taking the snapshot from publisher and making it available to the subscribers:
- It establishers a connection between publisher and subscriber.
- It acquires lock on the publisher tables when there is change happening on the tables.
- Copies the data from publisher and writes the same in snapshot folder.
- Once changes are done, it releases the lock on the publisher tables.
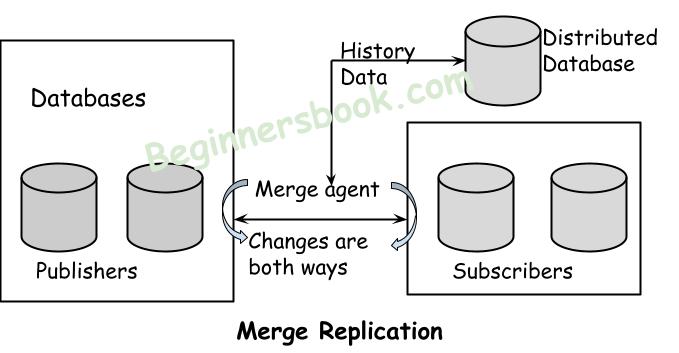
3. Merge replication
Similar to the transaction replication, it also starts with a snapshot of the publisher database. The further changes made to the publisher database are made available to the subscribers using triggers. When these triggers happen, the subscriber gets connected to the publisher and replicates all the changes that are happened to the publisher since last time it synchronized with publisher.
Merge replication allows publishers and subscribers to make changes in the database and these changes are replicated to other publisher and subscribers.
Replication Schemes
1. Full replication: In full replication, the entire database is available at every site of the distributed database. This approach provides full availability and performance. In this approach, even if there is a system failure, the database availability doesn’t get affected, thus this replication scheme is robust and durable.
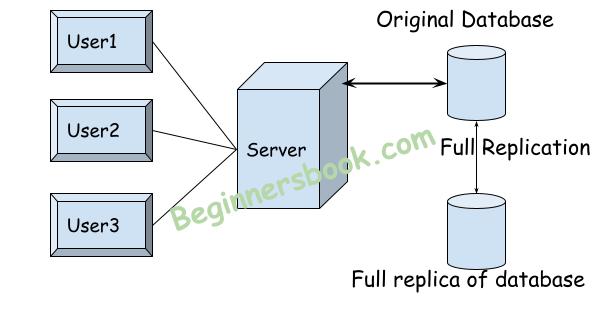
Advantages of full replication:
1. High availability
2. Best performance
3. Full recovery in case of failure.
4. Better load balance on every site of distributed database.
Disadvantages of full replication:
1. Requires high storage capacity.
2. Data redundancy as the data that is not frequently accessed is also replicated at every site.
3. Updates are slow as every changes has to be made live on every site of distributed database.
4. Maintaining data consistency at every site requires complex measures.
2. Partial replication: In partial replication, only the data that is frequently accessed is replicated on every site of distributed database.
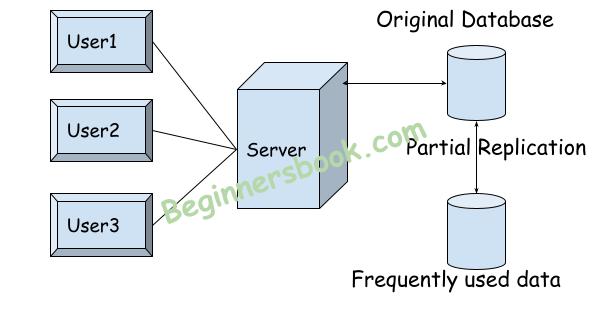
Advantages of partial replication:
1. Requires less storage capacity than full replication.
2. Provides good performance as the frequently used data is available at all sites.
3. Updates are faster as only important and frequently used data is replicated at all sites.
4. Maintaining data consistency is somewhat easier than full replication as the replicated data size is small.
Disadvantages of partial replication:
1. Doesn’t provide high availability for non-frequently used data.
2. No full recovery in case of failure of source database.
3. Poor load balance as the data that is not present can be accessed from source server only.