A database index is a data structure that helps in improving the speed of data access. However it comes with a cost of additional write operations and storage space to store the database index. The database index helps quickly locate the data in database without having to search every row of database. The process of creating an index for a database is known indexing. In this guide, you will learn various types of Indexes in DBMS (Database management system) with examples.
Real life example of Indexing
1. You must have read a book, the first few pages of book contains the index of book, which tells which topic is covered at which page number. This helps you quickly locate the topic in the book using the index. Without the index, you would have to scan the entire book to look for the topic which would take a long time.
2. In the library, the books are arranged on the shelf in an alphabetical order. If you are looking for a book starting with the the letter ‘A’ then you go to the shelf ‘A’. Here shelf naming with the letter ‘A’ is the index. Imagine if the books are not arranged in alphabetical order in shelves, it would take a very long time to search for a book.
Index structure in Database
The most common index data structure contains two fields.

1. First field is the search key, this is the column that a user can use to access the record quickly. For example, if a user is searching for a student in database, the user can use student id as a search key to quickly locate the student record.
2. The second field contains the address of the student record in the database. Remember indexing doesn’t replicate the whole database, rather it creates an index that refers to the actual data in database. This field is a reference to the data. If user is searching for a student with student id “S01” then the S01 is the search key and the second field of the index contains the address where the student data such as student name, age, address is stored.
Types of Indexes
1. Dense Index
2. Sparse Index
3. Clustered index
4. Non-clustered index or secondary index
5. Multilevel index
6. Reverse Index
1. Dense Index
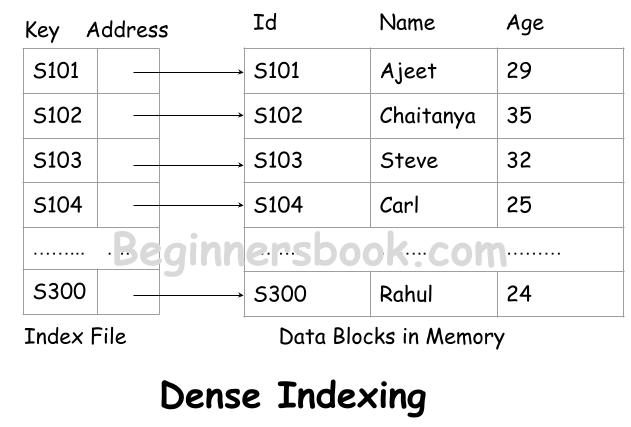
In Dense Index, there is an index for every record in the database. For example, if a table student contains 100 records then in dense index the number of indices would be 100, one index for each record in table.
If more than one record has the same search key then the dense index points to the first record in the database that has the search key.
The dense name is given to this index is based on the fact that every record in the database has a corresponding index in index file so the index file is very dense in this index based database.
Advantages of dense indexes:
1. Searching a record is faster compared to other indexes.
2. It doesn’t require the database to be sorted in any order to generate a dense indexes.
Disadvantages of dense indexes:
1. Requires more space as the index file is huge because it contains indexes for all records.
2. More write operations to generate index file.
3. It requires more maintenance as any change in any record would require a maintenance in index file.
2. Sparse Index
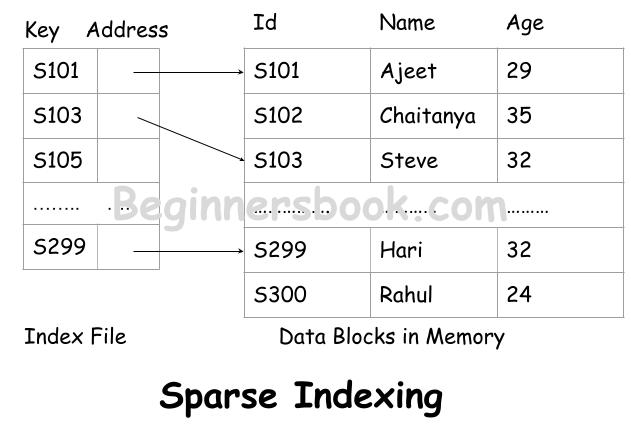
In this index based system, the indexes of very few data items are maintained in the index file. Unlike Dense index system where every record has an index entry in index file, in this system, indexes are limited to one per block of data items as shown in the following diagram.
In sparse indexing database needs to be sorted in an order.
For example, let’s say we are creating a sparse index file for student database that contains records for 100 students.
Student records are divided in blocks where every block contains two records. If index file contains the indexes for alternate records then we need to maintain indexes for only 50 records whereas in dense index system, we had to have 100 records in index file.
Advantages of sparse indexing:
1. It requires less storage space for managing the index file as it stores the indexes of few records instead of all records. This improves the performance.
2. Since limited entries need to be maintained in index file, it requires less write operations for generating a sparse index file.
3. It requires less maintenance compared to dense indexes.
Disadvantages of sparse indexing:
1. Searching is little slower than dense indexes as not all records have corresponding indexes and it requires a binary search to locate the search record.
2. Sparse index requires file to be sorted.
Difference between Dense and Sparse indexes
| Description | Dense | Sparse |
|---|---|---|
| 1. Performance | Search is faster as index for every data item is present. | Write operations to generate indexes are faster as indexes for few records needs to be generated. |
| 2. Prerequisite | No prerequisites | It requires the database to be sorted. |
| 3. Storage | More storage space is required. | Less storage space is required. |
| 4. Maintenance | Requires more time as every insert, update and delete operation in database requires maintenance in the index file. | Requires less maintenance as number of indexes are less compared to dense index system. |
3. Clustered Index
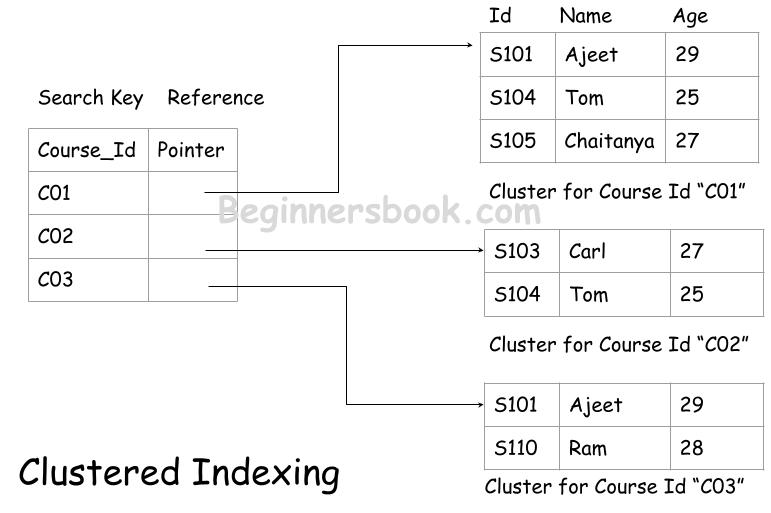
As the name suggests, in clustered index, the records with the similar type are grouped together to form a cluster and an index is created for this cluster which is maintained in clustered index file.
For example:
Let’s say students are assigned to multiple courses and we are creating indexes on course_id filed. In this case, all the students that are assigned to a particular course_id form a cluster and the index for that particular course_id points to this cluster as shown in the following diagram.
This helps in quickly locating a record in a particular cluster as the the size of the cluster is limited and smaller than the actual database so searching a record is faster.
One of the type of clustered indexing is primary indexing: In this type of clustered indexing, data is sorted based on the search key. In this type of indexing, searching is even faster as the records are sorted.
4. Non-clustered or secondary indexing
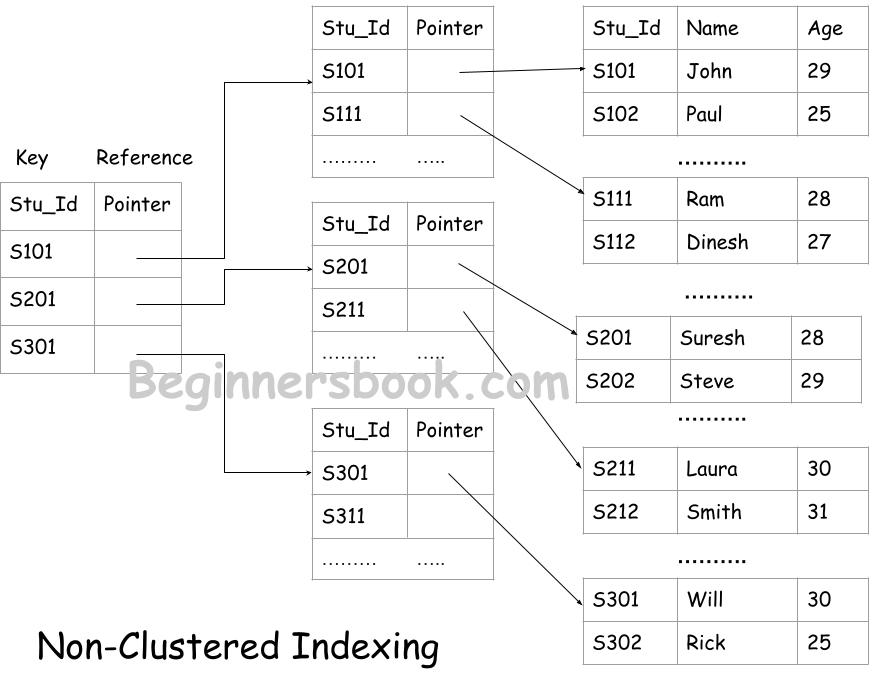
In non-clustered indexing, the indexing is done on multiple levels. This indexing is also known as secondary indexing.
For example, let’s say we have records of 300 students in database, instead of creating indexes for 300 records on the root level, we create indexes for 1st student records, 101st student and 201st student. This index is maintained in the primary memory such as RAM. Here we have divided the complete index file in three groups.
The second level of indexes are stored in hard disk, the primary index file is stored in RAM, refers to this file and this file then points to the actual data block in memory as shown below:
5. Multilevel index
In multilevel index strategy, the indexes are stored at multiple levels as shown in the following diagram. This strategy is especially used when there is a large amount of data items, thus the size of the index file is huge.
An index file with large number of records defeats the purpose of faster access and better performance as accessing a large index file itself gives poor performance.
To solve this issue, in this strategy, index are divided in multiple levels such as outer index blocks, inner index blocks, data blocks. The outer index blocks points to the inner index blocks and inner index blocks points to the data blocks. Managing indexes this way, we don’t need to access the whole index file as only those outer, inner and data blocks needs to be accessed that are matching the criteria of search key.
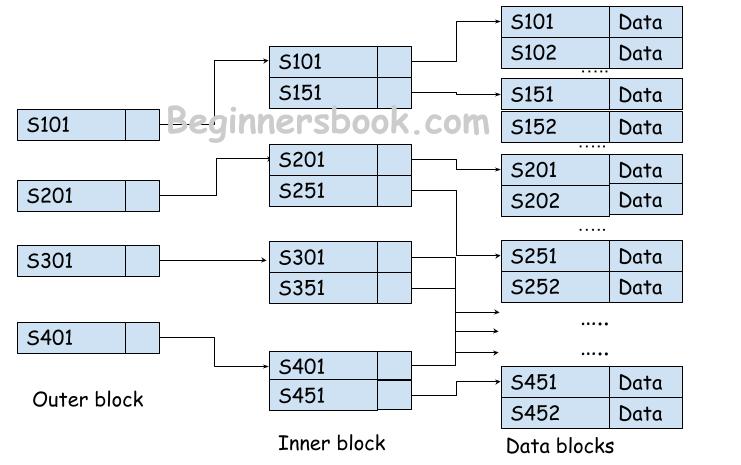
The disadvantage of multilevel index strategy is that it requires additional storage space to maintain this multilevel hierarchy of indexes.
6. Reverse Key Index
In reverse key index strategy, the search key value is reversed before it is written in the index file. For example a search key value 34568 becomes 86543 in the reverse key index file.
This strategy is used when the search key field in the index data structure represents sequence numbers where each key value is greater than the prior key value.
Reverse key indexes uses B-tree as data structures. The B-tree stores similar values in a single block such as the value 86543 and 86544 are stored in a single block which makes them easier to access.